|
August 2019
AutomatedBuildings.com
|
[an error occurred while processing this directive]
(Click
Message to Learn More)
|
|
Machine Learning to Apply Haystack
Tagging at Scale
To most
people, Machine Learning is a buzzword that somehow “magically”
spits out all the correct results. In this article, I’m hoping to lift
the hood and give a basic explanation of how our system acquires
results.
|

Lucy Kidd,
Data Scientist,
BUENO
Systems
|
At BUENO we bring in
data points from a variety of building systems, apply meaning to this
data using tagging models and use these to deliver value through energy
savings, smarter comfort control and data-driven maintenance tasking.
To make any use of the data we extract, we need to understand what that
point represents, to apply our intelligence effectively, we need to
understand the context behind each data point. The tagging models we
apply give our technology this context, allowing us to apply a common
set of algorithms to many different building types.
Our product uses its intimate knowledge of the context behind each
datapoint to gain insights into building operation, monitor control
strategies and develop predictive maintenance tasking. To ensure these
outputs are reliable, we need to apply our tagging models to each
building to a high degree of accuracy. In the not so distant past, the
process of tagging a site was extremely manual and time consuming for
our Deployments team, usually resulting in a level of human error. This
meant our product was expensive to deploy onto a site, and our
analytics were not as accurate as they could be due to incorrect tags.
As the company grew, we were creating more complex analytics and
bringing in buildings at a faster rate, meaning our previous methods of
tagging were becoming unsustainable.
I recently participated in the Haystack Connect 2019 conference held in
San Diego, where a large community gathered to share ideas on how to
best tackle the challenge of making the data we extract from the built
environment easily interpretable. The conference involved a rollout of
a new Haystack Tagging standard, as well as presentations on various
applications of Haystack. One pain point multiple presenters spoke of
was the labour intensity of applying tags on building systems. During
the conference, I was lucky enough to present BUENO’s solution to
speeding up the tagging process.
Introducing Unicron
Our solution to supporting the company’s growth, without exponentially
scaling the deployments team, was a machine learning tagging bot called
Unicron. We figured we could learn from using the numerous buildings we
had already poured our blood, sweat and tears into tagging as a
training dataset to infer what tags to place on new deployments. The
end goal is a user interface that our deployments team can use to
simply check suggestions the machine has pushed forward and accepting
or rejecting them.
To most people, Machine Learning is a buzzword that somehow “magically”
spits out all the correct results. In this article, I’m hoping to lift
the hood and give a basic explanation of how our system acquires
results. In short, Unicron is constantly examining how tags are applied
to our current sites and builds a model based on their learnings. This
model is then used to make inferences about new points that come in and
provide tagging suggestions to a Deployment Engineer.
How it learns
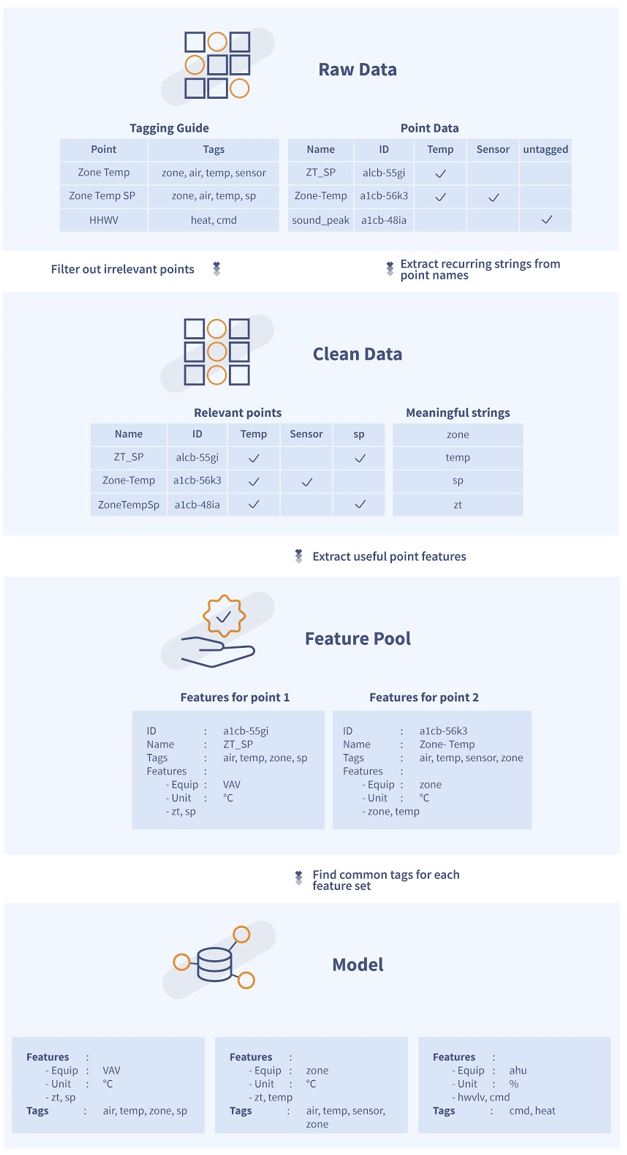
Figure
1. Basic information flow for Unicron learning cycle
As
figure 1. shows, the model is built by reading the BUENO tagging
guide and all tagged data points we have in our system. A tagging guide
is basically a big dictionary that tells our Deployments team what tags
need to be placed on what points; it is used in Unicron to inform the
algorithm what tags are relevant. An example of the raw point data is
shown in the figure; these tagged points are what the algorithm uses as
a training set for the model.
The raw data is cleansed, meaning all irrelevant data points and tags
are filtered out until only the useful information is left, this will
include point names, the units, a reference to the equipment it sits
under, and it’s tagged. The clean data also includes a long list of
meaningful strings. The meaningful strings will be any string
combinations that frequently appear in the names of the raw data
points.
Using the relevant points and meaningful strings, a feature pool is
built. The feature pool will have an entry for each point, consisting
of useful point features and some basic information. We have defined
useful features as:
- The type of equipment the point sits under
- The unit it reads in
- The kind of data it reads in (i.e. number, boolean)
- The meaningful strings that have been matched
within the name of the point
As can be referenced in Fig XX there is also an entropy value, this is
calculated based on how much of the point name has been matched to
meaningful strings, we use this as a proxy for the confidence that we
have completely understood what the point does.
The model-building algorithm will look at the feature pool and extract
all recurring pairings of feature sets and tags. The most likely
pairings of features to tags will be saved to a database. This database
will be used as a knowledge base to assume tags for new points.
All of the learning tasks involved here are run constantly, meaning
that when updates are made to the points, we currently have, or a new
building is deployed, the feature pool will start to update
immediately. Our model will slowly start learning from the new feature
sets it finds and updates itself accordingly. In this way, we can add
new tagging models or update our tagging model to align with the new
Haystack Tagging standard, without updating our tagging software.
How tagging suggestions are created

Figure 2. How suggestions
for new points are created
The
flow Unicron uses to create suggestions can be seen in Figure 2. We
will read in all points on a site as raw data and use some of the data
we have extracted during the learning stage to find the appropriate
tags.
The point features Unicron uses includes the point’s name, the type of
equipment it lives under, the unit it reads in and the meaningful
strings included in its’ name. The type of equipment that the point
lives under will have been tagged using scripts and hence will already
be known. The point’s features are extracted using exactly the same
method as in the learning process.
Tagging suggestions are built by matching these features to the feature
sets in the model. The confidence of a match is calculated as a mixture
of the proportion of the point name that we have matched to meaningful
strings (similar to the entropy mentioned previously), and the distance
between the feature sets matched.
How we use it to make tagging faster
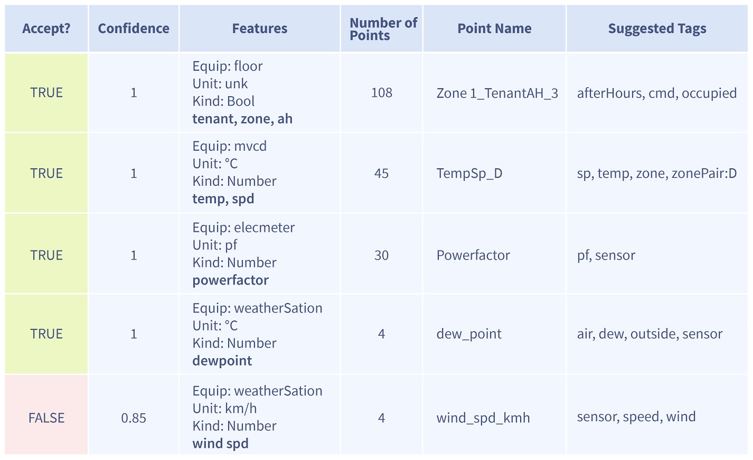
Figure 3. Example tagging
suggestions Unicron creates
When
we bring on a new site, our Deployments team will connect all of a
sites data points to our servers and start to read in histories. Next,
they will access our bot and tell it which site they want to tag, and
the bot delivers suggestions in a user interface similar to figure 3.
As you can see, the ‘Accept?’ the field will default to true when there
is 100% confidence, but to false when the confidence level is lower.
The Deployments team will check the suggestions and change the
‘Accept?’ field to ‘TRUE’ where necessary. The bot will
use this
feedback to make the appropriate tagging updates, leaving the
Deployments team only manually to tag those points that the bot had
incorrectly matched. On the next iteration of the learning process, the
bot will use these recently tagged points on this new site as feedback
and update the model with this new knowledge.
Results
On average Unicron will match 94% of a sites’ points to a tag set with
100% confidence. We find that most new sites that we bring in have very
similar naming patterns to those that currently exist in our system.
Hence direct matches to the model can often be made. The percentage of
points matched can decrease significantly when the points are unusually
named, or the site contains equipment we don’t currently have tagging
models for. We also found that points matched with 100% accuracy are
matched to the correct tags more than 98.1% of the time.
[an error occurred while processing this directive]Clearly,
the algorithm is not perfect and in need of continuous
improvement. In the future, we plan to improve the calculations we use
for our confidence metric, add further detail to the features we
extract from each point, update it to deal with different languages and
apply the tagging bot at an equip level. We have already
experienced some extremely valuable improvements to the time we spend
tagging and the quality of the tags applied to our current stack.
The deployments team estimate that using the bot reduces the time they
spend tagging by 50%. This decrease can be attributed both to the
improved User Interface that allows deployments to viewpoints with
identical features in a single row, as well as the convenience of
having suggested tags automatically available. This means they can
spend more of their time working on tagging the complex relationships
between equipment and use the bot to make the grunt work tagging
points. The ultimate result is a reduced price of entry to our platform
for our clients and greater job satisfaction for the deployment team.
In addition to using the bot to tag all new buildings we bring onto our
platform; we have used the bot to revise and update the tagging on our
current buildings. After this exercise, we saw a 60% decrease in
analytics bugs raised that were found to be tagging issues. Hence,
Unicron has greatly increased the accuracy of our algorithms, leading
to an immeasurable reduction of engineering time spent looking at
faulty analytics, and best of all, higher confidence in our algorithms.
Summary
At BUENO, we use detailed tagging models to make sense of the data we
ingest from buildings, but the process involved in tagging a site has
historically been very manual. Using a Machine Learning tagging bot has
allowed us to significantly lower our time spent tagging and increase
the quality of our algorithms. I hope this article helps to make sense
of the machine learning process and one way it can be applied to make
our lives in the Building Automation Industry slightly easier!
About the Author
Lucy
Kidd is passionate about leveraging her knowledge and studies to make
the world a better place. At BUENO systems she’s a developer of
analytics and tagging specialist, working towards the goal of making
our buildings better! Before starting her journey with BUENO she
studied Mechatronic Engineering and Computer Science degrees, and is
always learning about new data science techniques.
footer
[an error occurred while processing this directive]
[Click Banner To Learn More]
[Home Page] [The
Automator] [About] [Subscribe
] [Contact
Us]