|
November 2011 |
[an error occurred while processing this directive] |
|
Avoid the Crisis
Achieve Zero Downtime |
Roy Kok AutomationSMX |
| Articles |
| Interviews |
| Releases |
| New Products |
| Reviews |
| [an error occurred while processing this directive] |
| Editorial |
| Events |
| Sponsors |
| Site Search |
| Newsletters |
| [an error occurred while processing this directive] |
| Archives |
| Past Issues |
| Home |
| Editors |
| eDucation |
| [an error occurred while processing this directive] |
| Training |
| Links |
| Software |
| Subscribe |
| [an error occurred while processing this directive] |
Crisis; the defining moment in a career, the tipping point in a Stock Price, the shattering of a reputation. Any way you look at it, a Crisis is a pivotal moment that is best avoided.
In the terms of Automation, it can be characterized as a loss of production (downtime), possibly of a simple piece of equipment, or it can be extensive, affecting major portions of the building. It might be as simple as a failed fan, or downtime associated with a central heating system. We take it for granted, environments are so complex these days; be it Building Automation, Automotive Production, Pharmaceutical Manufacturing or Oil and Gas production, there will be downtime. We measure it, catalog it, and attempt to minimize it for most production environments.
Every instance of downtime is a micro-crisis. As downtime extends
in duration, or spreads in size, the crisis grows and becomes more and
more visible. As Automation Engineers, shouldn’t we be focused on
minimizing the crisis, or eliminating it altogether, especially for
systems that are out of sight and out of mind most of the time?
Are we giving enough focus to the right areas, or are we taking the
usual steps to designing our automation systems, not focusing on the
level of a “worst case scenario” type of crisis.
Murphy’s Law Exists for a Reason
If anything can go wrong (crisis), it will go wrong, and at the worst possible moment (major crisis). We all will agree that Murphy’s Law is a reality. Countless public examples exist, and most likely, you have personal examples of your own. But how often do you actually plan for Murphy’s Law?
Take some time to ponder that last paragraph… Sure, we all plan for one component failure, but what about a series of components? In your last downtime, what could have made it worse? What bullet did you dodge? A short time ago, I experienced a component failure and had a spare, but the spare failed a day later. Now add in some hypotheticals; no additional spares, it’s Friday at 5:00 PM, we run around the clock, and the engineer with all the know-how just left on a long deserved vacation. That’s a great example of a career defining moment.
The point is hopefully made; downtime can become extensive and
expensive in a hurry, and Murphy’s Law needs to be considered in
downtime price calculations. We can say “that will never happen”,
but lots of examples will prove you wrong.
The Goal should be Zero Downtime, not Minimal Downtime
But where to start? We’re used to working from the process level and upwards to the Control Room, starting with redundant sensors, redundant communications, redundant BAS Controllers. It’s the higher levels where our efforts often start to falter. These components start getting more and more expensive. Do I need a redundant SCADA system, redundant Historian or redundant Enterprise Interfaces?
Let’s take it a step further – Disaster Management. Suppose the control room was destroyed. Do you have a backup plan? I agree that under usual circumstances, this is pretty farfetched, but not if you are on a naval vessel. Closer to home, you may have heard of a steam line at a power plant that ruptures and destroys a control room. Or, more plausible in building automation, a fire safety system, spraying a server room, disabling its operation. Should this event be planned for? And if yes, what might you consider?
Taking it a step lower, we have Servers and Operator Consoles. At what level is their redundancy appropriate and have you considered that in your designs? Do you have spare Keyboards, Displays or CPUs? Are your backups up-to-date? Yes, you have a Client/Server architecture and can just move to a backup workstation. But what if the server fails? If your system is a single CPU HMI/SCADA, what are your options then?
I recently explored computer component failures with very interesting
results. Major components of a PC, the Graphics card, the
Motherboard, Disk Drive, etc. each typically have a failure rate in the
range of 3%, over a two year period. Add that up, as either one
will bring down a workstation or server, and you are looking at greater
than 10% chance of failure. Even the best and most respected
companies in the business can have issues. One leading computer
vendor for example, had a 22% failure rate on their PC workstations (a
total of 4.6 million computers over a three year period) due to a
faulty batch of capacitors. Imagine this fact - the average
server has over 5,000,000,000 (yes, that’s 5 Billion)
transistors. The question is not if there will be a failure, but
when one of the many servers making up your automation system will
fail.
Choices to Enhance Reliability and Deliver High Availability
Quality Hardware
At the server level, reliability is usually a matter of selecting a
quality brand, and protecting data with either Raid (Redundant Array of
Inexpensive Disks) or NAS (Network Attached Storage). This
approach will help to minimize downtime, and will protect your data,
but some level of downtime will continue to exist – defined by the
speed to server repair or replacement. Downtime in this case can
be measured in hours per incident.
Specialized Applications
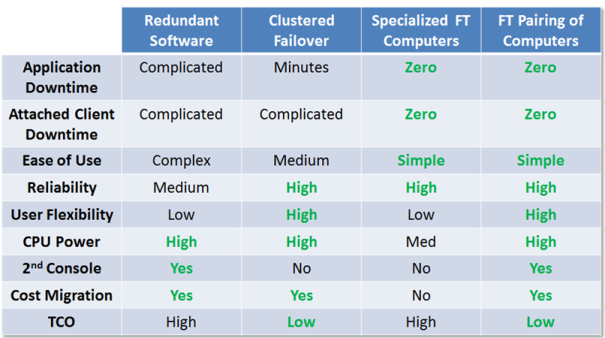
Many software manufacturers have developed application based solutions
for Redundancy. These are oriented to an approach to managing
failures in communications, services in their software solutions, or a computer. Their software
leverages either Client/Server computing techniques where Client
applications will automatically fail over to a redundant named server,
or where software components are designed with the intelligence to fail
from one Service to another. The quality and scope (levels of
redundant functionality) of these solutions vary greatly from vendor to
vendor. As a software solution, you have the ability to upgrade
hardware while retaining your investment in High Availability
software. I refer to this as “Cost Migration” over time.
These solutions can all be coupled with High Availability hardware
schemes to deliver the ultimate Zero Downtime solution.
[an error occurred while processing this directive]Clustered Computers and Virtual Environments
The next step in downtime minimization is to make sure you have a
backup computer ready to accept the transfer of an application, and
perform that transfer automatically. This is the most common
solution implemented by IT departments for their business
systems. Most business systems are transaction based and the
failure of a server means the transactions either stop or become
backlogged, ready to be recovered when the application resumes.
The most common providers of this technology are Citrix, Microsoft and
VMware. These solutions offer virtual machine (VM) computing
environments. Applications are loaded into a Virtual Computer
that is running on a hardware platform in a computer cluster.
Should the hardware fail, the virtual machine (and all applications
running inside it) is restarted on another resource in the
cluster. Downtime is measured in minutes per incident and in more
complex client server environments, clients to the server application
will experience both downtime (that should be added to the total) and
the need to automatically reconnect to the new Virtual Machine instance
(an additional risk of failure). While these solutions are well
suited to database transactions or Web Servers, where a few moments of
downtime can be tolerated, they are not optimal for real-time computing
applications such as HMI/SCADA and analytic environments that are
closely tied to process controls and optimization. Cost Migration
is also maintained in a Virtualization Environment. In today’s
thin client environment, where operator access to systems are through
Web interfaces, going blind during a Virtual Machine restart is far
less than optimal.
Proprietary High Availability Computers
Specially designed computers, with fully redundant components, exist as
a Fault Tolerant platform on which to run your applications.
These are typically Server oriented and can run headless, supporting a
Client/Server environment. While this computer offers fault
tolerance, there is still one keyboard, video display and mouse to
manage the system. Downtime is designed to be zero with this
offering, and components can be purchased from the vendor and replaced
while the system continues to operate. This solution does not
deliver cost migration of the High Availability investment. The
cost of the High Availability hardware is incurred again when an
upgrade to a higher performance platform is needed. Stratus
Computer is the provider of a proprietary High Availability computing
platform.
High Availability Pairings of Market Leading Platforms
An alternative approach to a proprietary hardware platform comes in the
form a pairing of two standard COTS (Commercial-Off-The-Shelf)
computers, through the use of specialized High Availability (Zero
Downtime) software. This delivers a number of new benefits to the
user including the ability to leverage the latest computing power on
the market, the computers from your favorite supplier, and the ability
to locate them together, or in a Split-Site configuration.
The pairing of the computers is performed through a dedicated high
speed Ethernet connection between the computers. Specialized HA
(High Availability) software links the computers, creating a virtual
computing environment for your applications. The virtual
environment leverages the components of each computer. If an
Ethernet port fails on one machine, the virtual environment seamlessly
switches to the Ethernet port on the other machine. The same
applies for a disk failure. If the CPU fails, the application
fails over to the CPU of the other machine.
This is a Zero Downtime environment that will recover easily.
Just replace the failed server and the application software
automatically mirrors the storage, and brings the new computer back
into lockstep operation. Raid arrays are not a requirement.
The leveraging of two standard computers brings another benefit, the
ability to have a completely separate console - Keyboard, Video
Display, and Mouse. If used in an operator environment, the user
has the ability to work from either machine, at any time.
This solution, by leveraging COTS computers with High Availability software, does deliver Cost Migration over time. This form of High Availability is applied to many markets beyond Building Automation, and is used on specialized computers – Industrial Panel Computers or Embedded Computers used in Military or Aerospace applications. As a Zero Downtime solution, Client computers and IT Systems never have to deal with reconnections or fail-over to a separate server. By combining standard software products with COTS offerings, a Fault Tolerant Pairing of computers is likely to deliver the most flexibility and the least Total Cost of Ownership (TCO). Marathon Technologies is the primary provider of Zero Downtime Software for pairing COTS platforms.
Summary
While High Availability is always a goal, the areas of HMI/SCADA,
Historians, and Business Analytics would benefit greatly from Zero
Downtime – something that is achievable today. The avoidance of a
crisis, compounded by the possibility of Murphy’s Law, is an attainable
goal. Varying solutions exist in the market and are proven
solutions to minimizing your downtime and ensuring your job security by
dodging the crisis bullet.
About the Author
Roy Kok has worked in the Automation Industry for over 30 years, in the
areas of OPC Technology, Communications, HMI/SCADA software,
Historians, Embedded Software, and Industrial Computing. Today he
offers business development services under his company,
AutomationSMX. You can reach Roy at roy@automationsmx.com.
[an error occurred while processing this directive]
[Click Banner To Learn More]
[Home Page] [The Automator] [About] [Subscribe ] [Contact Us]