There has been a lot of conversation about data, modeling, ontologies and the need for independent data layer (IDL). Is there a universal understanding of the definition? Not in my experience, nor is there a universal understanding of how to apply it to building systems, smart buildings, or enterprise software in the PropTech industry? You don’t have to go very far back to see the debate James Dice hosted on this very topic. I realize some of this was staged, but so many of the ideas shared in the debate are ideas shared by many in the smart buildings community.
I’d love to start a conversation about the need for independence in the data layer. First, I think we need to level set on the definition of the “data layer” before we focus in on the independence of such a layer.
Enterprise Software
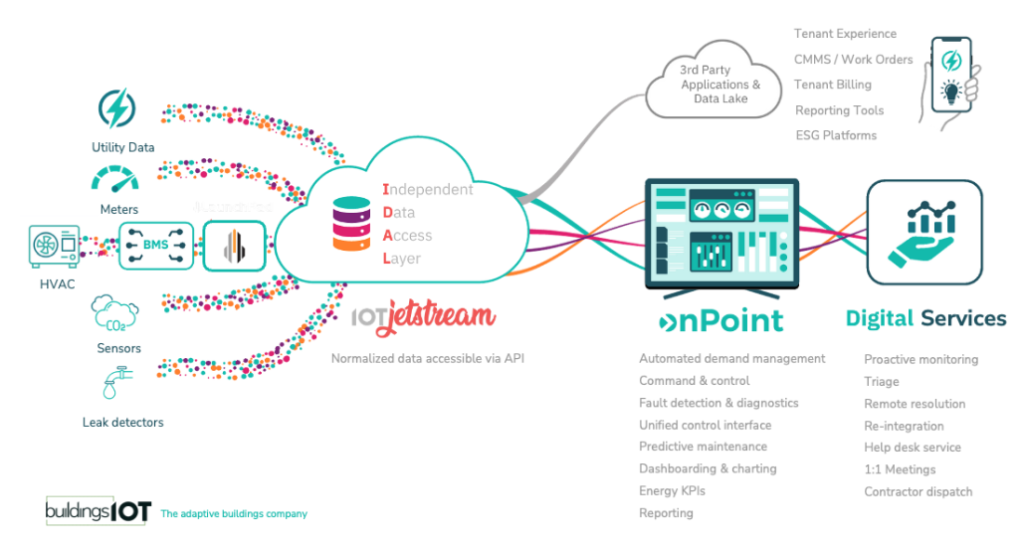
The IDL is potentially the most important decision an enterprise can make when entering the area of smart buildings, adaptive buildings, energy efficiency, or whatever other term du jour is being used. When done properly, the IDL provides meaningful access to processed, transformed, and modeled data for the built environment. With this data, applications can deliver real insights, reporting, and take action. When a group of applications is selected, all deriving data from disparate data sources, using many methods of providing identity to the data, businesses run into the same problem they had before the implemented all the technology. Departments are on different wavelengths on the same issues, all looking at this through their own lens, using their own source of truth. Sound familiar?
Data bodies of water (rivers, ponds, lakes, oceans)
Most of us are familiar with the concept of a data lake, but in most cases the data stored in a data lake is void of structure, allowing it to be filled with data from multiple sources including raw, unprocessed, and processed data. This data then needs to be processed and/or transformed for applications to take full advantage of the data. This can put undue strain and increase the time to value for application providers. This is not to say data lakes and other version of data warehouses can’t be part of the data delivery stack, but the specific use of the data is important to understand if it is used. Another challenge with this paradigm comes to light when access to near-real-time data or if write-back is required.
Source of Truth
The source of truth is another concept often heard when discussing the IDL. In some cases, the IDL is the source of truth, but this paradigm severely limits the type and breadth of data in the IDL. If we are bold enough to expand the IDL to IDaL, where the ‘a’ refers to access, we open up the possibility for multiple sources tof truth to be accessed via the IDL, but with key relationships established among the data from each of the sources of truth.
Data Identity and Relationships
A proper IDL for the built environment will contain a strong data model to create strong identities and relationships for all of the data stored (or accessed) via the IDL. There are many open source ontologies (OAP, Brick Schema, Project Haystack, Google DBO, Real Estate Core, etc) out there for providing identity to the data and creating relationships to entities and spaces, both physical and virtual. The importance of choosing a specific ontology is less important that choosing one and remaining consistent across your portfolio of buildings.
APIs are like toothbrushes: everybody’s got one but nobody wants to use anyone else’s. — Michael Grant
API
Another term that is thrown around as if there is a universal understanding. I don’t know if Michael Grant really came up with the quote above, but James Dice gives him the credit and who am I to argue. At its core, and API provides applications access to data from a single source, or multiple sources. An proper IDL will have a robust API that can be used to provide secure authenticated access to the data, in context of entities and spaces. There are different type of API options out there and none of them are interchangeable. It is important the the API be modern, scalable, and very well documented. New types of data and relationships will need to be added frequently given the ontologies will continue to expand with the universe of the built environment.
Independence
We now come to the concept of independence. Some are veering away from this word, opting instead for the word integrated. It is not some important to me, so I think the bigger picture is missed. The Data Layer should be independent from the source of truth AND independent from the applications. This does not stop the IDL from storing data, processing data, transforming data, or applying the ontology. I am also not suggesting that the company making the IDL should not create an application to use the data. This is what we do. However, the IDL is completely independent of the application layer and is not a required component of the IDL.
Does Anyone Care?
Back to the heart of the question. I think people care…a little. For most, the concept is still a bit abstract and it doesn’t hit home until they want to change application vendors and realize the integration, data modeling, and relationships all have to be recreated. Even once this is realized, most head down the same path again. The reasons are plentiful and most of the time, sound rational. For application vendors, this adds to the stickiness of the product as the barrier to change is high. For building owners and application users, this can be maddening, but it has yet to impact buying decisions at scale. Will this change? I don’t know. Regulations, data governance, reporting requirements and application independence may start to move the needle to put the IDL at the core of the conversation. We will see.